The AudioMulch Blog is written by AudioMulch's creator Ross Bencina. It discusses the in-depth nitty gritty of what AudioMulch is, how it works and what you can do with it. The blog is aimed at AudioMulch users who have mastered the basics and want to journey deeper into AudioMulch's capabilities.
If you're new to AudioMulch or want to brush up on the basics we invite you to watch our video tutorials.
Synthesizing the human voice is not a new idea (see for example Make's post about the Bell labs VODER). Recently I thought I'd see how far I could get making AudioMulch speak. The basic idea was to make a patch that mimics the human vocal tract, set up the parameters to make different vowel sounds and then control it using the Metasurface. My goal was to get AudioMulch to say "Audio Mulch," in the end I only got as far as "Audio." The result is pretty basic but covers some interesting ground...
The Human Vocal Tract
The human vocal tract consists of the vocal cords, which vibrate creating the pitched sounds of the voice, along with the cavities of the throat, mouth and nose which resonate the sound made by the vocal cords. Resonances created by the vocal tract (called formants) accentuate and attenuate different frequencies depending on the shape you make with your tongue and mouth – thus creating different vowels and tone colors. Non-voiced sounds are made by air turbulence (think "t" and "shhhhhh"). Here's how I simulated it with AudioMulch:
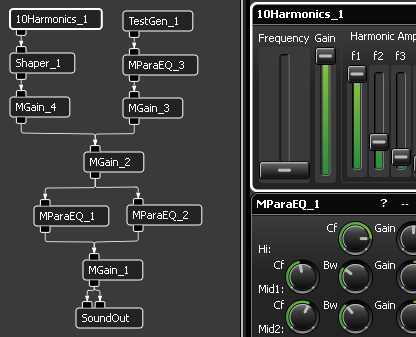
Screenshot of the voice synthesis patch.
The idea is to approximate the vibrating vocal cords using a 10Harmonics contraption fed into a Shaper to add higher harmonics, then filter that using the sweepable peaking filters in two parallel MParaEqs (parametric equalisers) to approximate the the vocal resonances. The TestGen running in to MParaEq_3 is used for the 'd' in 'Audio'.
Formant Filtering
The next task was to tune the parameters of the equalizers to create the different formant resonances. This meant setting the center frequency and bandwidth of each filter according to known values for each vowel sound. I used the values from a book about one of the early speech synthesizers called MITTalk ("From Text To Speech, The MITTALK System," Cambridge University Press, 1987) but you can find similar tables on line. There's one on the Formant wikipedia page and googling for "table of formant frequencies" brings up some interesting results for different languages. You could also work them out with a spectral analyser, but I digress.
Speech Articulation with the Metasurface
To program movements between the vowels I used AudioMulch's Metasurface window. The Metasurface provides a way to snapshot all the parameter settings in an AudioMulch document and recall them at once. More interestingly, you can use the Metasurface to smoothly slide from one set of parameter settings to another – a bit like the way the human vocal tract smoothly moves from one shape to another when you speak. AudioMulch version 2.0 will add the ability to automate the interpolation location of the Metasurface making it easy to record and refine coordinated parameter changes – I've used that feature in the video below.
For each vowel sound I wanted (and some I later didn't use) I tuned the equalisers then took a Metasurface snapshot, giving it the same name as the phonetic name of that vowel sound. I then placed each vowel in a line on the Metasurface in the order I wanted (and did quite a bit of fiddling to get it sounding right). Then I automated the Metasurface Interpolation_X parameter to scan through these snapshots moving from left to right. Then I looped the sequence. I also automated the volume of the vocal tone (MGain_4) and the noise for the 'd' sound (MGain_3) separately.
The Result
The result is shown in the following screencast. Once the original has looped a couple of times I deconstruct the Metasurface mapping, disable the automation and scan around the different formants with the mouse. [I must apologise for the apparent jerkyness of the parameter changes, the screen recorder was making the mouse input somewhat jerky.. download the patch below for the full smooth real-time control experience.]
Video showing the automated Metasurface saying "Audio".
Needless to say, the acoustics of the human vocal tract are somewhat more complex than a waveshaped oscillator and four peaking EQ filters. But it does give you an idea of the kind of complex articulations you can coordinate with the Metasurface. I've made a version of the voice synthesis patch that works with AudioMulch 1.0 (no Metasurface automation, but it can be played with the mouse). You can download it here.
If I had time to improve it I would probably play with automating the frequency of the 10Harmonics to give it more expression, and of course, finish it to say "Audio Mulch". Perhaps that will be done in time for the AudioMulch 2.0 release. Speaking of the version 2.0 release, see the version 2.0 info page for some bad news (the release has been delayed, sorry!) and some good news (I'm opening the beta program to all existing users on May 1).
 Subscribe
Subscribe